
美国出口禁令之下,英伟达又为中国“阉割”一颗芯片(组图)
本文转载自腾讯新闻,仅代表原出处和原作者观点,仅供参考阅读,不代表本网态度和立场。
10月17日,美国更新出口管制标准,要求先进芯片性能超过特定阈值,即需要申请出口许可。在严苛的限制条件下,英伟达针对中国市场的特供版H800、A800两款芯片也面临禁售,以下为美国商务部对先进芯片性能的划定标准:
总算力之和≥4800 TOPS ,
总算力≥1600,且性能密度≥5.92;
2400≤总算力<4800,且1.6<性能密度<5.92;
总算力≥1600,且3.2≤性能密度<5.92。
面对新的管制条例,英伟达给了两个解法:其一,沟通美国商务部申请许可,给特定的中国客户“开白”;其二,针对新的管制条例,再次定制全新的特供版本。
刚刚举办的第三财季电话会议上,英伟达首席财务官科莱特·克雷斯确认了这一消息。克雷斯表示,英伟达正在与中东和中国的一些客户合作,以获得美国政府销售高性能产品的许可。此外,英伟达正试图开发符合政府政策且不需要许可证的新数据中心产品。
01 H800是如何“阉割”成为H20?
英伟达试图开发的新的特供版,即业内盛传的H20、L20等产品,最新消息显示,相关产品的上市计划已经延后至2024年第一季度。
问题在于,H20等全新特供芯片的研发、设计、生产,完全跳出了常规芯片的节奏,英伟达是如何在短时间内拿出这套特供解决方案?
它的答案就是我们这篇文章要讨论的关键问题之一:后道点断生产工艺,用大家更为常用的词汇总结即——阉割。
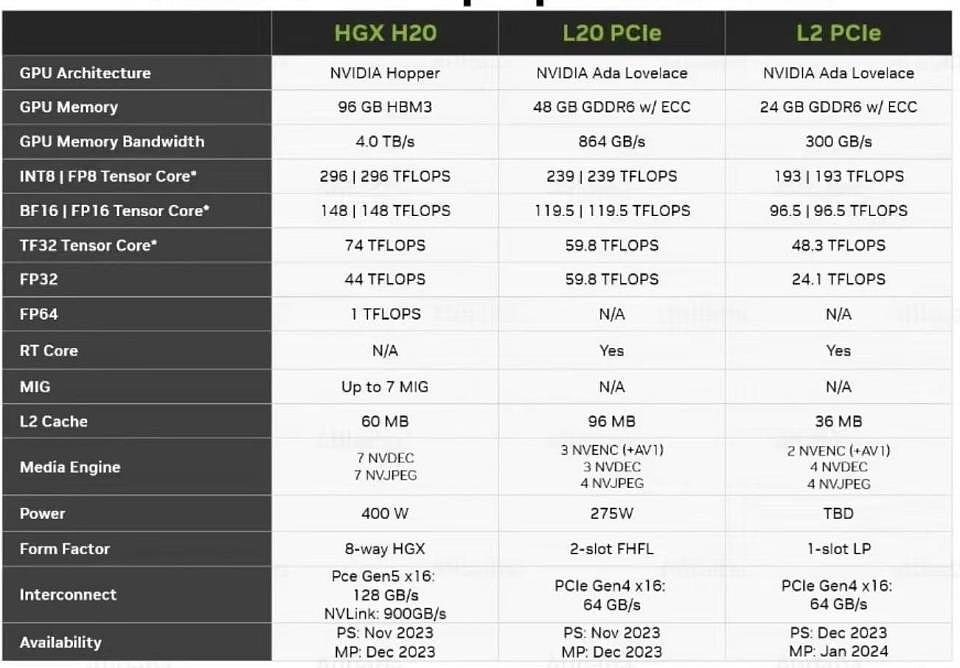
HGX H20 - L20 PCIe - L2 PCIe - 产品规格
按正常的设计、生产周期和产品发布节奏来推断,特供中国市场的H20 / L20等型号的芯片在这个时间节点发布,不太可能是重做光罩、重新投片的产物,一个相对合理地推论——即它们是通过半导体后道的物理点断工艺的改造+再封装,进而推出的新SKUs。
点断工艺是半导体制造的后道工序(BEOL)中的改造方法,可以在无须重做光罩的前提下使用一些管/线修补工艺,包括表面激光点断、CoWoS层面点断,甚至通过隧道镜手工雕线。
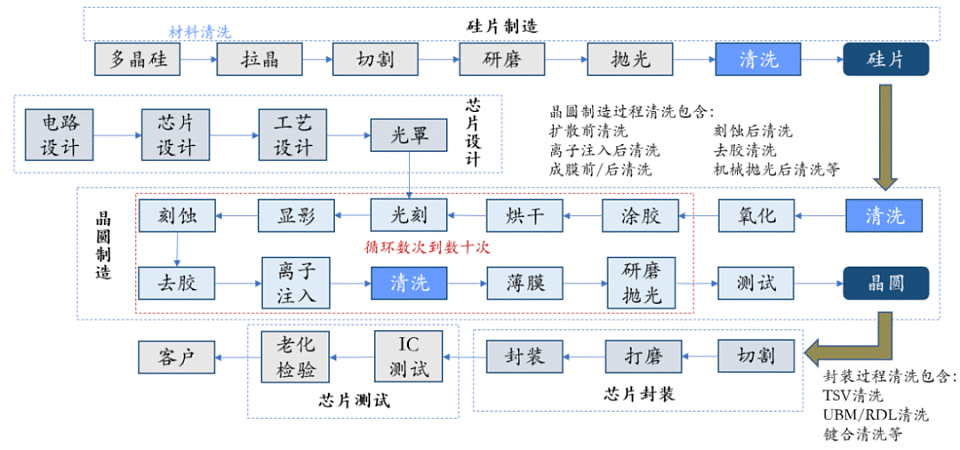
芯片制造主要流程,来源:东吴证券
可以假定一下这样的场景,代工英伟达H800的台积电南科Fab18A、台中Fab15B和台中先进封装5厂的洁净室里,此前降规生产的几批次裸片,还没来得及切割、镀上金属线和电极,还未封装成H800和L40S,转而通过后道点断生产工艺再封装成H20、L20。
02 表面激光点断是半导体制造传统艺能
行业惯例来说,一颗数字逻辑芯片的缓存大小(Cache Size)、底层物理互连(PHY channels)都可以通过在后道封测环节重修/点断做失效屏蔽处理的,尤其是针对低分数裸片的改造方法算是几十年的传统艺能,例如早期的奔腾、赛扬处理器的重要区别之一就是点断缓存。
倘若是局部微小部分,曾经可以手工完成(相当于微雕);面积稍大的部分,可以重新设计Layout预留点断位置,再由机器完成点断失效。
一种内置数字显示的温度传感器设计版图
实操上,通常的晶圆厂都会配置专业设备,由激光直接在裸片上切割线路/沟槽,而在亚利桑那钱德勒市的Intel Fab42工厂里,还有直接在专用隧道镜下面手工雕刻晶体管的设备,宣称是原子尺度的,不同于寻常的扫描隧道显微镜,几年前Intel有个宣传视频,提到这台设备,据传全球持证的操作手不超过14人。
其实在平面晶体管以前,显微镜手雕不算是高难度动作,但进入FinFET以后,由于垂直方向的3D栅极结构,手雕设备的代价和操作员就变得遥不可及了。
具体到H20/L20,这两款特供产品,是如何通过H800、L40S降规而来?可以先看看相关参数
H20:对应H100/800系列,Hopper架构(HBM3、2.5D CoWoS封装、NVLink)
L20:对应L40S系列,Ada Lovelace架构(GDDR6,2D InFO封装,PCIe Gen4)
注:固件相应修改;
回顾H100/H800相同架构之间比较关键的底层物理互连(SerDes PHY)的差异,H100降规阉割成H800,可以通过局部物理点断失效处理来实现;但相比之下,H20虽然与前面两款产品同构,但推测割掉的Dark Si面积可能较大,不确定常规点断操作是否不值得,也许需要重新做Layout。
但是除了底层物理层互连(SerDes PHY)的区别,还有双精度浮点计算(FP64)单元面积、张量核(用于矩阵、卷积类计算任务)单元面积的区别,这部分不好定论,但可以推测是类似利用物理冗余设计并加以屏蔽的操作,毕竟如今的设计方法学都是推动模块化的,流片后的测试原本就会有70分 die与90分 die的区别,以及GPU芯片上也不止一个FP64,局部操作物理点断失效也是合理的。
03 设计冗余为点断创造条件,也是大厂基操
举个例子:A、如今市面仍可见的Intel F系列CPU,就是点断显核的70分die;B、Apple Si的前两代,官宣8核NPU,实际有9个,就是设计冗余。
以上这些,在晶圆制造工序中也算是基本操作,特别是中试厂/线,Alpha - Beta流片的过渡期间,有小错就会直接手改,不会返回修改掩膜重新流片的。
从芯片设计者的角度来看,设计冗余度是在芯片开发流程中原本存在的,因为前道光刻过程是强调高良率的,具体到失效晶体管数,测试环节判断模块级别的良率,坏点可以直接电路割断,后续引线、封盖工艺流程都不变。
例如3年前,Intel曾向市场推出过不带显核的F系列CPU,就是物理降规/阉割的产物,点断显核,重新封装销售。但是该款芯片偶尔耗电巨大,经用户投诉,建环境验证后发现就是原本通过物理点断失效的显核在接电之后不受控制而导致的莫名电源故障。
这个案例反映的情况就是我们上文所讲的,同一条流水线,经过点断失效的芯片,后续的导线/引脚和封装过程不变,可以继续销售。尤其早期Intel 10nm的良率很低,积压很多这样的低分片,才会把显核失效的芯片加印F标继续销售。
如今这个“冗余度”可能有很大空间,毕竟H100已然是814平方毫米的大芯片,几乎接近光罩尺寸边缘(26mm*33mm=858mm2)。而如今发布的H20降规型号,大概是H100 15%的性能,但是其物料成本几近相同。
04 封装层面点断可操作性、经济性更好
除了在逻辑芯片表面的激光点断工艺之外,还有针对某些特殊位置的点断要求,比如CoWoS中介层的点断。
CoWoS作为台积电的2.5D封装方案,可以使得多颗芯片封装到一起,互连和内存等器件均通过硅中介层互联,达到了封装体积小,功耗低,引脚少的效果。
相比表面激光点断,在CoWoS的前道部分——即CoW部分是硅通孔和中介层——在该层面操作点断,做差异化,反而更经济,也更容易保证良率。
因为算力逻辑芯片和I/O 芯片是分列的,可以屏蔽底层物理互连的通道,也可以缩减HBM3内存性能,而且在硅中介层修改差异化更容易,相比全部在逻辑芯片上修改的代价更低,因为中介层上操作的线宽精度可以较低,甚至点断最上面那层金属的线宽即可。
但是,CoWoS中介层上面是只能够屏蔽物理互连和HBM内存,但是无法屏蔽FP64单元、Tensor core单元这样的计算逻辑芯片面积,这就需要补充用到前文所说的在逻辑die表面点断失效的方法。
另外,正常情况下,物理点断失效的电路是不能从外部第三方察觉的,且工艺不可逆;尤其如今芯片都是十几层金属,裸片的表面修改了,上面金属层是看不穿的,除非是用到反工程的透视扫描。
综上,我们看到进一步特供/降规生产的H20/L20等型号,可以判断是H800和L40S的裸片的后道物理点断工序的改造产物,同时重新封装、重新修改固件,成为新的SKUs。
回想NVIDIA之前积压的、原本销往中国的50亿美元的GPU产品尚未交付,如今返厂做了后道改造才得以如此快速地发布新的SKU,那么猜测国内厂商的50亿美元订单也许会转换为这三个型号。
05 “阉割”后的H20的能与不能
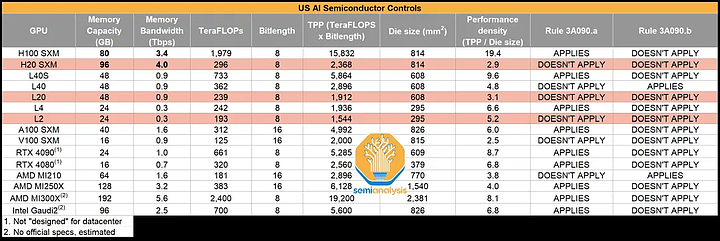
核心AI芯片相关参数及出口管制情况,APPLIES对应受管制,DOESN'T APPLY对应不受管制
如下是针对H20与H100/H800/A100的产品横向比较,比较维度包括“产品规格、单卡和集群算力效能、物料成本、定价体系”等四个方面:

集群综合算力方面,H100/H800目前是AIDC算力集群的顶流部署;其中H100理论扩容极限是5万张卡集群,最多可达10万P算力;H800最大集群是2-3万张卡,合计4万P算力;A100最大集群是1.6万张卡,合计9600P算力。
然而对于H20,其集群的理论扩容极限是5万张卡,以单卡算力0.148P(FP16/BF16)计算,集群合计提供7400P算力,远低于H100/H800/A100。

基于NVIDIA H800的8卡服务器模组
同时,基于算力与通信均衡度预估,5万张H20合理的整体算力中位数约为3000P左右,倘若H20面对千亿级参数模型训练,恐怕捉襟见肘,需要集群网络拓扑有更大的外延扩展。
但从HGX H20的硬件参数综合来看,几乎把美国商务部性能密度禁令中严格限制的算力门槛以外的指标全部拉满,显然是定位为一颗训推通用的处理器。
只是针对LLM大模型业态而言,实际使用H20做千卡分布式训练,虽然大部分有效利用时间都是GPU上的矩阵乘加计算的时间,通信和访存的时间占比缩小,但毕竟单卡算力规格较低,超限度的千卡集群扩展反而会使其费效比降低,H20更适用于垂直类模型的训练/推理,不容易满足千亿参数级LLM的训练需求。
需要注意的是,选用更多低规格、更廉价的GPU并联集群,试图追平或是超过一台超高算力的GH200效能,这是一种悖论。
因为这种方案的掣肘很多,环境搭建和运行的ROI并不高。因为在算力利用率、并行策略的执行、集群综合能耗、硬件成本和组网成本等等方面都不可能获得理想方案;H20集群与A800集群效能可以同比,对比H100/GH200集群效能则是不实际的。
H20的基本规格方面,算力水平约等于50% A100和15% H100,单卡算力是0.148P(FP16)/ 0.296P(Int8),900GB/S NVLink,6颗HBM3e(显存的物料与H100 SXM版本配置相同,即6*16GB=96GB容量),die size同样都是814mm2 。
考虑到H100 GPU单卡物料成本中的HBM颗粒成本独占55%-60%,整卡的物料成本约3320美元(H20成本相近,甚至由于增配的L2 Cache以及追加了点断工序而成本更高,且相比H800更加增配了HBM3容量和NVLink lanes带宽),那么对应最终的渠道定价规则,H20的渠道单价可能与H100/H800处于相近水平。
同比参考几个市面流通价格(来自某一线互联网公司和某一线服务器厂的渠道货价):
- DGX A800 PCIe 8卡服务器约145万元/台,NVLink版本200万元/台
- DGX H800 NVLink版本服务器,国内渠道报价约310万元/台(不含IB)
- DGX H100 NVLink版本服务器,香港渠道报价约45万美元/台(不含IB)
- H100 PCIe单卡报价约2.5-3万美元,H800 PCIe单卡尚不确定,且单卡流通渠道不正规
本文转载自腾讯新闻,仅代表原出处和原作者观点,仅供参考阅读,不代表本网态度和立场。







 +61
+61 +86
+86 +886
+886 +852
+852 +853
+853 +64
+64


